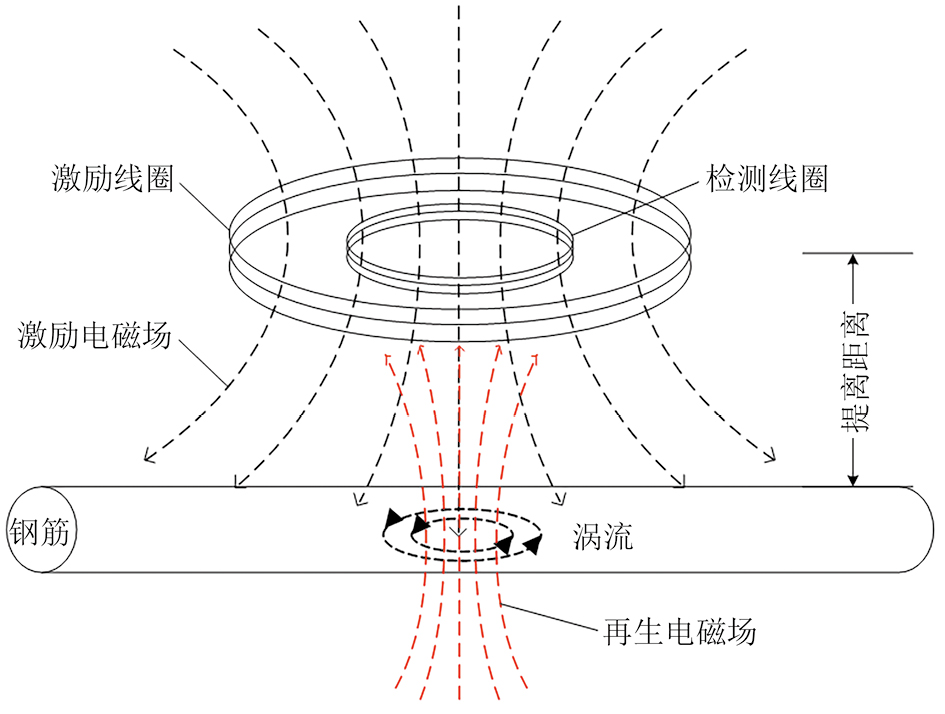
图 1 钢筋涡流检测原理示意

随着电力基建工程规模的不断扩大,钢筋作为钢筋混凝土结构类建筑施工中的必需材料,其质量直接影响着工程的质量安全。钢筋直径是衡量钢筋质量的重要参数,因此,准确测量钢筋直径成为保证电力基建工程安全稳定运行的关键。
工程上钢筋直径检测方法有破坏法和无损检测法。无损检测技术可[1-3]在不破坏材料结构的前提下,获取混凝土内部的钢筋信息。
常用的混凝土无损检测方法有雷达波法、射线扫描法、电磁感应法。
雷达波法[4-6]利用电磁波在不同介质中的传播特性,将高频电磁波以宽频带短脉冲的形式发射至混凝土内部,再利用接收天线接收反射波并进行分析,从而确定材料的内部结构和状态。射线扫描法[7-8]主要是采用X射线和γ射线高能电磁波,通过设备加速器对待测构件进行穿透检测,然后根据得到的图像进行判别和识别。这两种方法存在仪器体积大、检测成本高、可能对人员有伤害等弊端。
电磁感应法[9-10]是利用电磁感应原理,通过接收感应回来的二次感应磁场信号强度分析混凝土构件中钢筋的位置及保护层厚度,具有仪器设备小、造价低、对人体无危害等优点。近年来,电磁涡流检测技术受到越来越多的重视。
同时,为了提高精度,越来越多的智能算法应用于钢筋直径检测中,如BP神经网络[11-12]、GA-BP[13]改进神经网络、SVM(支持向量机)[14]、SVR(支持向量回归)[15]等。
相比于单一智能算法,集成算法[16]通过结合多个不同的基学习器,能够减少单一模型的偏差和方差,从而显著提高预测模型的准确性。此外,集成学习模型在处理噪声和异常值时的表现也更加稳定,能够提高模型的泛化能力。在实际应用中,集成算法在提升光纤陀螺温度补偿[17]、预测加工刀具[18]的剩余使用寿命等复杂问题上,表现出良好的性能。
针对提高检测精度的目标,文章提出了基于随机森林-支持向量机Stacking集成算法的混凝土中钢筋直径涡流检测方法。笔者首先设计了钢筋直径涡流动态检测试验过程,获得了检测信号样本,并进行了数据预处理,最后采用基于随机森林-支持向量机的Stacking集成算法,构建了混凝土钢筋直径预测算法。
混凝土中钢筋直径涡流检测技术基于法拉第电磁感应原理[19-21],通过测量因铁磁性材料切割磁感线或处于变化磁场中而产生的涡流和感应电压来实现材料结构的检测,其原理如图1所示。
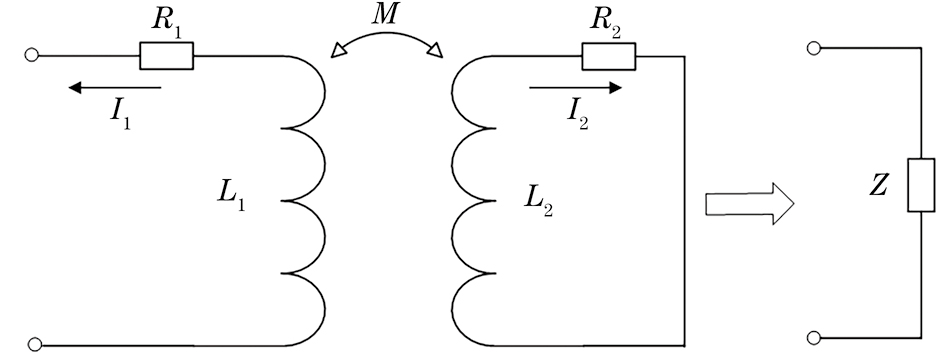
涡流检测时,通过测量检测线圈的感应电压变化,能够推断出钢筋的特性。若将钢筋直径涡流检测效应类比为变压器,钢筋视作一个短路线圈,则钢筋(短路线圈)与检测线圈(变压器的另一部分)之间的相互作用类似于变压器的工作机制,涡流效应等效图如图2所示。
如图2所示,检测线圈L1类比于变压器一次侧,R1为一次侧的等效电阻。钢筋的短路线圈L2类比于变压器二次侧,R2表示二次侧的等效电阻。检测线圈与钢筋的短路线圈存在互感系数M,即
| (1) |
式中:k为耦合系数,取值范围为0~1;L1,L2为变压器一次侧和二次侧的等效电感。
由基尔霍夫定律
| (2) |
| (3) |
式中:j为虚数单位,ω为角频率,U为电压。
令
| (4) |
即存在如下关系
| (5) |
根据式(1)~(5)可得,通过检测线圈上的电压、电流曲线可获取一次侧等效阻抗Z的特性。L1、R1反映了检测线圈的特性。L2、R2反映了钢筋的特性。M反映了检测线圈与钢筋之间的提离效应特性。
综上所述,合理地设计检测线圈(即L1、R1固定),有规律地改变检测线圈与钢筋直径的距离(M可变),获取检测线圈上的电压、电流曲线(Z特性),则可分析出钢筋的特性(例如直径等)。
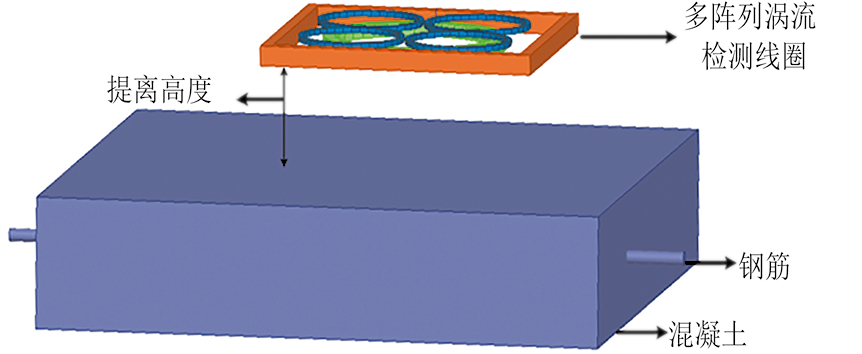
采用ANSYS MAXWELL电磁场仿真软件建立钢筋直径涡流检测的三维有限元模型(见图3),研究在不同直径钢筋条件下的多阵列涡流检测线圈响应信号,实现混凝土中钢筋直径检测。混凝土参数设置如表1所示。
| 参数 | 混凝土 | 钢筋 |
|---|---|---|
| 体电导率/(S · m-1) | 0.001 | 0.01 |
| 密度/(kg · m-3) | 2 300 | 4 600 |
| 相对介电常数 | 7~10 | 1 000 |
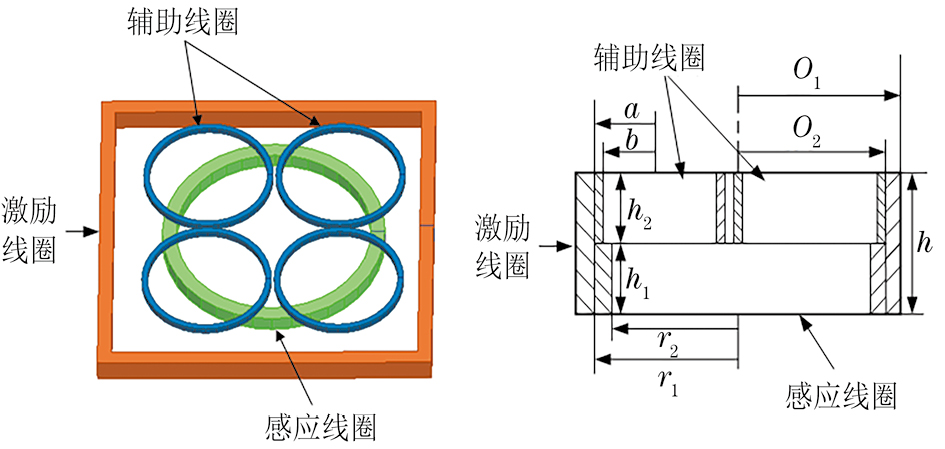
多阵列涡流检测线圈模型如图4所示,最外围的大线圈为激励线圈,其中O1为激励线圈的外半径,O2为内半径,h为高度,N1为匝数。位于中心的圆形线圈为感应线圈,其中r1为感应线圈的外半径,r2为内半径,h1为高度,N2为匝数。4个水平放置的圆形线圈为辅助线圈,其中a为4个辅助线圈的外半径,b为内半径,h2为4个定位线圈的高度,N3为4个定位线圈的匝数,其参数设置如表2所示。
| 参数 | 激励线圈 | 感应线圈 | 辅助线圈 |
|---|---|---|---|
| 外径 | R1=240 mm | r1=80 mm | a=47 mm |
| 内径 | R2=220 mm | r2=70 mm | b=45 mm |
| 高度 | h=10 mm | h1=5 mm | h2=5 mm |
| 匝数 | N1=340 | N2=340 | N3=110 |
采用涡流检测技术测量钢筋直径,当探头与钢筋之间的距离变化时,涡流的分布和强度会发生改变,从而使得感应电压也随之变化,笔者据此设计动态检测试验过程,寻找钢筋直径在不同提离高度处时与检测线圈上响应信号的对应关系,具体步骤如下。
(1)步骤1:选择激励信号。采用正弦波作为激励信号,加载到激励线圈上。激励电压为12 V,频率为1 000 Hz。
(2)步骤2:在固定钢筋直径下动态测量。固定钢筋直径,例如在钢筋直径为6 mm的情况下,多阵列涡流检测线圈从提离高度15 mm到35 mm动态等间隔地选取21个位置点进行测量,获取感应线圈和4个辅助线圈的电压响应信号。
(3)步骤3:多组钢筋直径下动态测量。
采用国家标准钢筋10组,直径分别为6,6.5,8,12,14,16,18,20,22,25 mm,重复步骤2的动态测量过程。
通过上述动态检测试验过程,共采集210个样本,采集的部分样本参数如表3所示。
| 提离高度/mm | 电压幅值/V | 钢筋直径/mm | ||||
|---|---|---|---|---|---|---|
| 辅助线圈1 | 辅助线圈2 | 辅助线圈3 | 辅助线圈4 | 感应线圈 | ||
| 15 | 0.812 1 | 0.749 3 | 0.772 7 | 0.839 8 | 2.040 5 | 6 |
| 25 | 0.874 2 | 0.756 0 | 0.754 7 | 0.869 8 | 2.121 3 | 18 |
| 20 | 0.829 9 | 0.756 8 | 0.761 4 | 0.795 2 | 1.976 4 | 6.5 |
| 16 | 0.859 1 | 0.766 4 | 0.746 4 | 0.825 5 | 1.992 5 | 16 |
| 31 | 0.842 0 | 0.768 4 | 0.730 9 | 0.857 3 | 2.025 9 | 8 |
| 18 | 0.835 5 | 0.777 3 | 0.731 5 | 0.794 6 | 2.000 3 | 14 |
| 17 | 0.885 5 | 0.780 2 | 0.747 1 | 0.806 0 | 2.198 0 | 16 |
| 16 | 0.853 9 | 0.780 3 | 0.776 4 | 0.809 9 | 2.074 6 | 12 |
| 23 | 0.888 3 | 0.780 4 | 0.764 0 | 0.804 5 | 2.105 9 | 20 |
| 18 | 0.847 3 | 0.780 5 | 0.710 0 | 0.754 3 | 1.927 4 | 16 |
| 33 | 0.827 7 | 0.781 0 | 0.754 3 | 0.833 1 | 2.071 7 | 20 |
| 27 | 0.897 0 | 0.784 6 | 0.735 6 | 0.806 0 | 2.069 8 | 25 |
| 32 | 0.889 3 | 0.786 4 | 0.770 8 | 0.800 0 | 2.172 0 | 22 |
| 34 | 0.865 4 | 0.786 6 | 0.807 8 | 0.826 0 | 2.172 7 | 14 |
| 29 | 0.863 5 | 0.786 7 | 0.800 3 | 0.803 8 | 2.074 2 | 12 |
| 20 | 0.808 7 | 0.788 6 | 0.747 6 | 0.748 9 | 1.877 7 | 8 |
采用Stacking集成学习框架(见图5)进行钢筋直径预测,该框架通过结合多个基学习器的预测结果,并使用这些结果作为新特征输入到元学习器中,以提高模型的预测性能。
(1)数据预处理
采用钢筋直径作为模型输出,将提离高度、辅助线圈1~4的电压幅值、感应线圈电压幅值作为模型输入。对模型输入、输出进行标准化处理,以消除量纲影响。
标准化公式为
| (6) |
式中:z为标准化后的值;x为原始数据;μ为数据的均值;σ为数据的标准差。
(2)数据集划分
将标准化后的输入输出数据,按照n∶1的比例随机划分为训练集和测试集。
(3)K折交叉验证
将原始训练集随机分成K等份,每个基础学习器将其中的1份作为K折测试集,剩下的K-1份作为K折训练集。使用K折训练集训练每个基学习器,并对K折测试集进行预测,合并每个基学习器的预测结果,作为元学习器的训练集。
(4)基学习器的选择
支持向量机(SVM)[22]是一种基于最大间隔原则的监督学习算法,通过寻求找到一个超平面,尽可能多地穿过训练数据点,降低预测值与真实值的误差。由于SVM擅长捕捉数据中的复杂边界,能够有效处理非线性问题,同时对噪声和异常值具有较好的鲁棒性,故其能够为Stacking模型提供稳定且具有区分性的特征表示。
定义优化目标函数为
| (7) |
式中:w为权重向量;C为正则化参数,用于控制模型对训练数据的拟合程度;ζi为松弛变量,用于处理那些不完全符合ε-insensitive loss函数的数据点。
预测函数可写为
| (8) |
式中:
核函数用于在高维空间中映射数据,使得数据在高维空间中线性可分,考虑到钢筋直径预测是一个非线性回归问题,文章采用RBF核作为核函数,即
| (9) |
式中:
(5)元学习器的选择
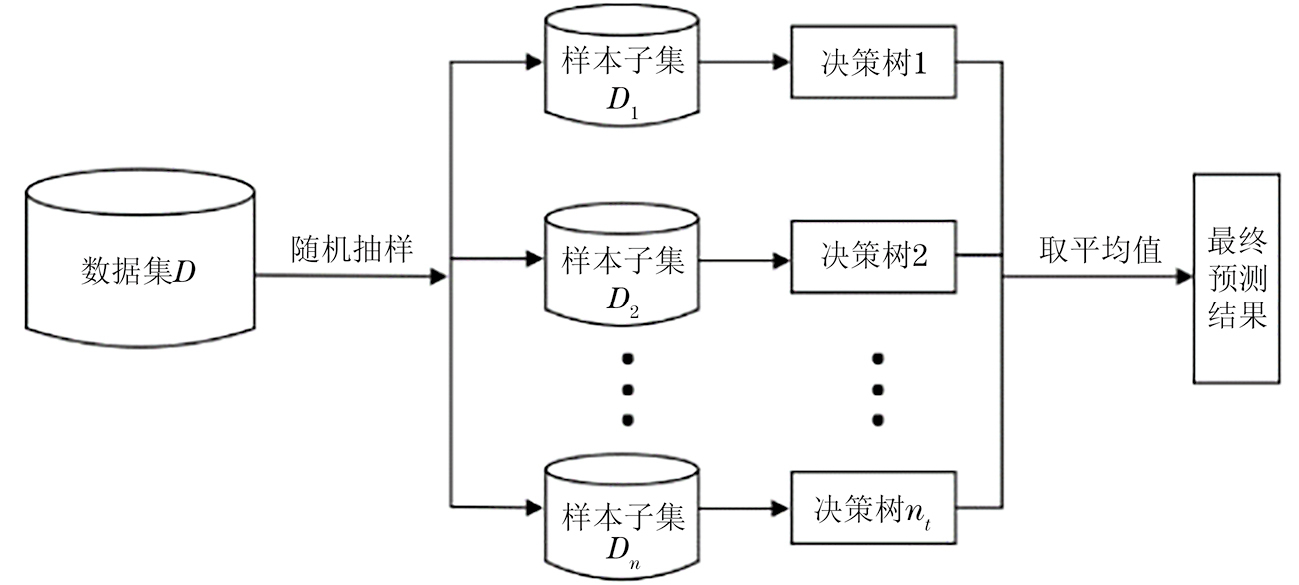
随机森林(RF)[23]是由L.BREIMAN等提出的一种将Bagging集成方法与随机子空间方法结合在一起的机器学习算法。其通过构建多个决策树,再对它们的预测结果进行投票或者取平均值来得到最终的回归结果。
随机森林可以很好地整合多个基学习器的预测结果,有效融合SVM的预测结果,从而进一步提升模型的泛化能力和预测准确性,具体实施步骤如下。
(1)步骤1:初始化模型参数。设置决策树的数量为nt和最大深度dmax。
(2)步骤2:随机抽取样本。从训练数据集D中采用Bootstrap抽样法有放矢地随机抽取n个样本子集
(3)步骤3:随机选择特征。在每个节点分裂时,随机选择特征。
(4)步骤4:分裂节点。训练数据集中包含m个特征,则在每个节点随机选择
(5)步骤5:回归预测。在预测时采用取平均值的方法对多棵决策树的预测结果进行汇总。
RF模型的构建流程如图6所示。
为了评价单一模型与集成模型的预测效果,采用均方误差(MSE)、平均绝对误差(MAE)和决定系数(R2)来衡量各模型的预测性能,具体计算公式为
| (10) |
| (11) |
| (12) |
式中:n为样本数量;yi为真实值;
MSE衡量的是预测误差平方的平均值,MAE衡量的是预测误差绝对值的平均值,二者都衡量预测误差,但MSE对大误差更敏感;R2衡量模型的解释能力,值越大表示模型拟合得越好。
采用SVM、随机森林和SVM - 随机森林集成等3种不同算法建立钢筋直径预测模型。按照4∶1的比例将210组数据中的168组划分为训练集,剩余的42组为测试集。
为了对比集成预测模型的预测精度,考察SVM模型和随机森林的模型参数设置。
在设置模型参数时,需要考虑SVM模型中正则化参数C、核函数参数γ、ε参数对预测效果的影响,进行如下分析。
(1)保持γ=0.1和ε=0.1不变,设置C=50,100,150,SVM模型的预测误差和决定系数值如表4所示。
| 参数设置 | MSE | MAE | R2 |
|---|---|---|---|
| C=50 | 1.975 55 | 1.033 14 | 0.952 44 |
| C=100 | 1.949 14 | 1.010 98 | 0.953 08 |
| C=150 | 1.896 39 | 0.994 87 | 0.954 34 |
由表4可以看到,随着C增大,均方误差和平均绝对误差小幅度减小,决定系数也变化不大,而且考虑到C越大,模型会对训练数据中的噪声和异常值越敏感,从而出现过拟合。所以选择C=100较为合适。
(2)保持C=100和ε=0.1不变,设置γ=0.01,0.1,1,SVM模型的预测误差和决定系数值如表5所示。
| 参数设置 | MSE | MAE | R2 |
|---|---|---|---|
| γ=0.01 | 3.991 37 | 1.769 23 | 0.903 91 |
| γ=0.1 | 1.949 14 | 1.010 98 | 0.953 07 |
| γ=1 | 0.832 75 | 0.682 54 | 0.979 95 |
由表5可以看到,随着γ增大,误差减小,决定系数也逐渐增大,但增大的幅度降低,同时由于较大的γ值会使模型更加关注于训练数据中的局部特征而可能导致过拟合,故选择γ=0.1。
(3)保持C=100和γ=0.1不变,设置ε=0.1,0.2,0.5,SVM模型的预测误差和决定系数值如表6所示。
| 参数设置 | MSE | MAE | R2 |
|---|---|---|---|
| ε=0.1 | 0.832 75 | 0.682 54 | 0.979 95 |
| ε=0.2 | 0.812 80 | 0.705 16 | 0.980 43 |
| ε=0.5 | 0.849 15 | 0.757 48 | 0.979 56 |
由表6可以看到ε在增大的过程中,误差先减小后增大,决定系数也先增大后减小。在ε=0.2时,误差最小,决定系数最大,故选择ε=0.2。
参数设置时,要考虑随机森林模型中决策树的数量nt和最大深度dmax对预测效果的影响,进行如下分析。
(1)保持nt=100不变,设置dmax=2,5,8,随机森林模型的预测误差和决定系数值如表7所示。
| 参数设置 | MSE | MAE | R2 |
|---|---|---|---|
| dmax=2 | 20.368 55 | 3.902 38 | 0.509 62 |
| dmax=5 | 5.678 43 | 2.156 66 | 0.863 29 |
| dmax=8 | 4.053 74 | 1.647 03 | 0.902 41 |
由表7可以看到,dmax=2时,误差较大,预测效果较差,增加到5时,误差明显降低,拟合效果也较好,但继续增大时,误差变化不大。由于该参数控制了决策树的复杂度,较小时不能很好地解释模型,但过大时会使决策树结构过于复杂,在小样本上的预测出现过拟合,故选择dmax=5。
(2)保持dmax=5不变,设置nt=30,50,100,随机森林模型的预测误差和决定值分别如表8所示。
| 参数设置 | MSE | MAE | R2 |
|---|---|---|---|
| nt=30 | 5.209 85 | 2.052 68 | 0.874 57 |
| nt=50 | 5.146 63 | 2.032 71 | 0.876 09 |
| nt=100 | 5.678 43 | 2.156 66 | 0.863 29 |
由表8可以看到,随着决策树数量的增多,均方误差和平均绝对误差先减小后增大,在nt=50时,误差和决定系数表现最优,故选择nt=50。
SVM模型对噪声和异常值具有很好的鲁棒性,而RF通过构建多棵决策树并进行平均,能够有效地处理高维数据并控制过拟合。Stacking模型结合了RF和SVM的优点,使用SVM作为基学习器来捕捉数据的非线性关系,然后利用RF作为元学习器来学习这些预测结果的组合。利用不同模型的多样性可以提高模型的泛化能力。
将SVM模型、随机森林模型、SVM-随机森林集成模型应用于钢筋直径预测中,将测试集数据输入到3个模型中进行性能评估。3个模型的预测值与实际值的对比如图7所示。
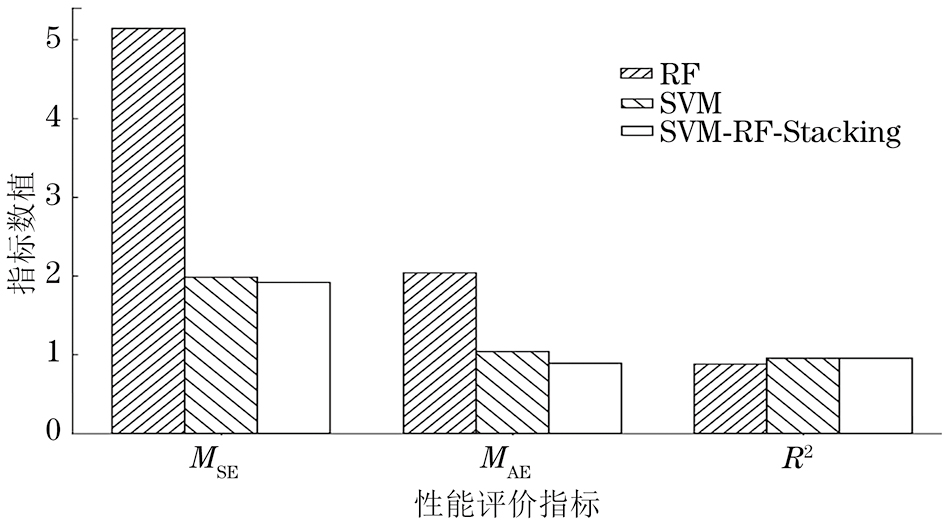
SVM、随机森林与集成模型的性能指标如表9所示,各模型的性能指标对比如图8所示。可以看到,相较于单一模型,集成模型的预测效果明显变好,均方误差下降了63%,平均绝对误差则下降了56%,而决定系数提高了9%。
| 模型名称 | 性能评价指标 | ||
|---|---|---|---|
| MSE | MAE | R2 | |
| SVM模型 | 1.983 76 | 1.029 73 | 0.952 24 |
| 随机森林模型 | 5.146 63 | 2.032 71 | 0.876 09 |
| 集成模型 | 1.914 52 | 0.888 42 | 0.953 91 |
文章利用钢筋直径涡流动态仿真试验,在不同条件下获取大量检测数据,并将随机森林-支持向量机Stacking集成算法应用到混凝土钢筋直径涡流检测中。试验结果表明,集成模型比单一模型的预测效果更好,精度更高,在混凝土钢筋直径检测领域具有更好的应用前景,对钢筋混凝土涡流检测仪器的研制具有指导意义。
文章来源——材料与测试网
浙江国检检测技术股份有限公司 版权所有 【暂无】 百度统计
全国统一服务热线:400-1188-260
客服手机号:13372307781
电话:400 1188 260 质量投诉 +86-573-86161208
邮箱:shhgj@chinazbj.com
地址:浙江省嘉兴市海盐县武原街道丰潭路777号
备案号:浙ICP备05056915号
 浙公网安备 33042402000106号
浙公网安备 33042402000106号
技术支持:追马网
 客服微信号
客服微信号
 微信公众号
微信公众号