图 1 失效分析案例文本挖掘方法框架示意

失效分析是对产品故障进行系统化分析和研究的过程,涉及工程学、材料科学、计算机科学等多个领域[1]。失效分析工程师通过对失效部件的服役环境、工艺类型及断口特征等多种关键因素进行综合分析,找到失效的根本原因,并制定有效的预防和改进措施[2]。有效的失效分析对提高产品的可靠性和安全性具有重要意义,其广泛应用于航空、航天、航海、汽车制造、电子设备和医疗器械等多个领域。近年来,对产品的可靠性要求日益提高,同时产品的功能、结构、受力、服役环境等越来越复杂,传统的人工失效分析方法难以从大量数据中找到失效的关键因素,以及因素间的耦合关系,且人工法受专家经验的影响较大[3],分析过程须耗费大量精力。
为了应对失效分析不断增大的复杂性,自然语言处理和数据挖掘等技术成为提高失效原因诊断效率的有效手段,近年来该技术在失效分析领域得到广泛应用。随着失效分析工作的逐年开展,失效分析案例逐渐增多,蕴含的数据价值不断显现。应用自然语言处理技术对大量失效分析文档进行文本挖掘,提取文本特征,并结合各类数据挖掘方法对文本特征进行分析,对识别失效模式和潜在失效风险等极具应用价值[4]。LIU等[5]应用自然语言处理技术对管道事故叙述文本数据进行文本挖掘,并结合K-means聚类分析方法,识别造成管道事故的影响因素,为管道系统的维护和安全管理提供了科学依据。HALIM等[6]综合分析了多个管道事故数据库,开发了一种基于大数据和机器学习技术的因果模型,揭示了不同因素之间的复杂关系,研究成果在提高管道事故风险预测准确性等方面具有重要作用。CHOKOR等[7]对建筑领域大量事故报告进行文本挖掘,采用聚类分析方法对建筑事故报告类别进行划分,提高了事故报告的处理效率。杨晓等[8]设计并建立了船舶系统典型材料失效分析案例数据库,通过对船舶系统失效案例的多层级分类,提高了失效分析工程师获取信息的效率。
关联规则挖掘是数据挖掘领域中的重要研究课题之一,其在发现事物间隐藏关联关系的数据挖掘场景下具有良好的表现。失效原因排查及诊断过程涉及的失效因素种类多,各因素间相互影响[9]。应用关联规则对失效分析案例数据进行分析、挖掘,形成失效分析关联知识并保存,对产品失效原因的推理具有重要意义。
然而,自然语言处理和数据挖掘等技术在失效分析领域起步较晚,且聚焦在具体的领域,如管道事故、换流站故障[10],以及轨道电路故障等,缺少可以覆盖不同类型应用场景的统一模型框架,且现有研究对失效文本的挖掘方法通常为聚类分析、神经网络等,这些方法对分析结果的可解释性较差,不利于对产品失效原因进行推理[11]。与此同时,现有的关联规则挖掘研究大多与算法效率提升有关,较少研究失效案例分析与应用的改进方法[12]。因此,在失效分析领域,如何根据失效案例数据的实际特点及结构,结合自然语言处理技术,应用关联规则挖掘方法实现失效分析案例的分析挖掘,建立失效因素关联路径,辅助提高失效原因排查的效率、准确性,成为亟待解决的问题。
针对在复杂应用场景下,传统失效分析技术难以在大量数据中发现失效因素和失效原因间潜在关系的问题,笔者提出了一种结合自然语言处理技术、关联规则挖掘算法的失效分析案例文本挖掘方法,同时发明了基于Apriori算法的两阶段失效分析案例文本关联规则挖掘方法,建立了失效分析案例文本挖掘方法框架;对某船舶单位的失效案例文本进行了有效验证,研究结果对产品失效原因诊断和故障作用机制解释方面具有重要的辅助借鉴作用。
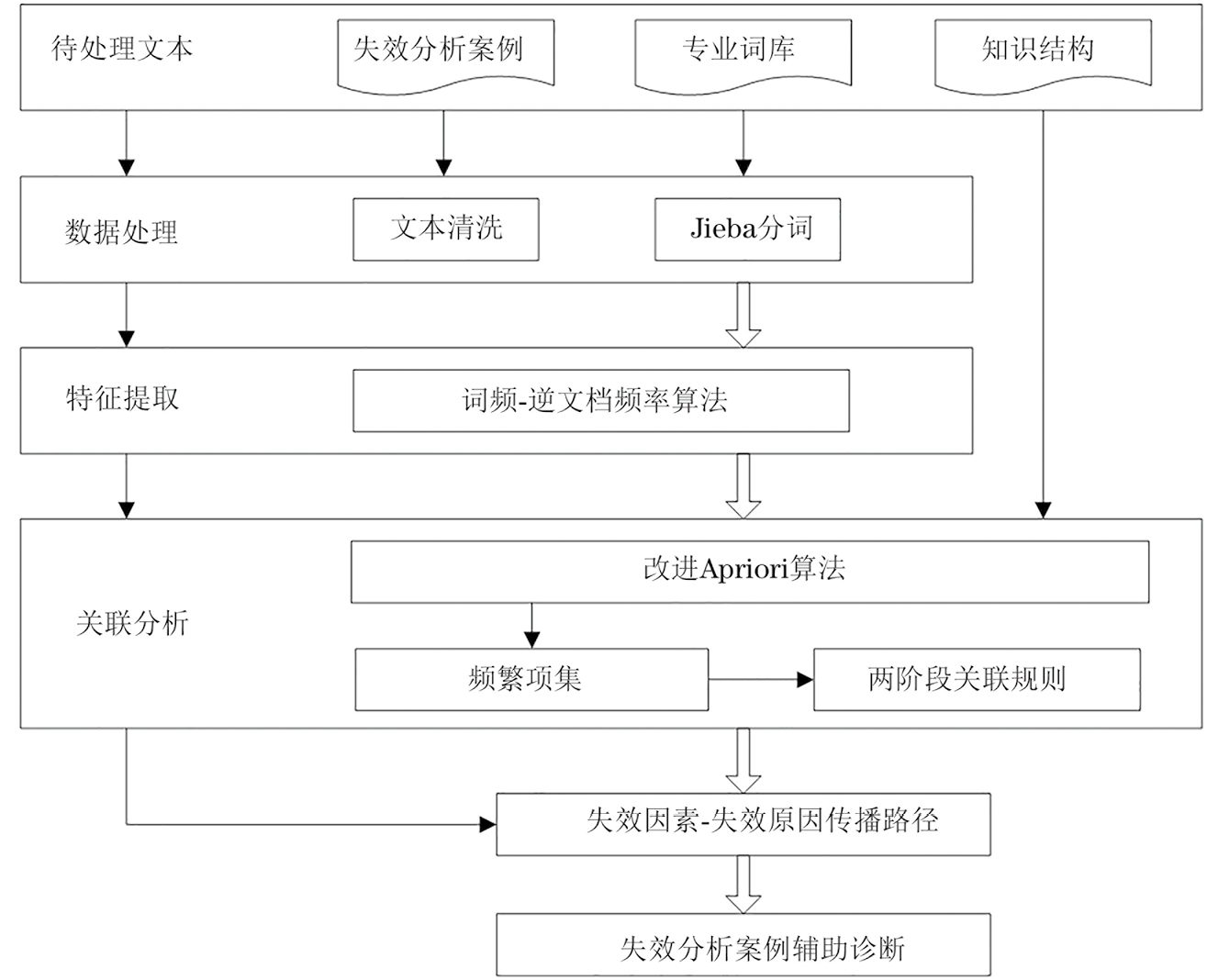
结合失效分析工程师的实际工作过程、失效分析案例的数据特征及其结构,提出失效分析案例挖掘方法(见图1)。该方法用于提取失效因素、失效模式,以及失效原因间的关联规则,挖掘失效因素至失效原因间的传播路径,可为现场设备失效分析辅助诊断及预防提供决策支持。
首先,对失效分析案例文本数据进行预处理,结合构建的失效分析行业领域的专业词典,采用分词处理方法初步去除无意义词项,得到分词处理后的失效分析案例文本数据。其次,对于分词处理后的失效分析案例文本数据,基于TF(词频)-IDF(逆文档频率)算法进行文本特征提取,转换为词项文本矩阵,获取案例文本的关键词及其对应的权重。然后,基于Apriori算法分两个阶段对词项文本矩阵进行关联分析,挖掘频繁项集及关联规则。最后,基于失效分析案例文本关联分析结果,建立失效因素及失效原因间的传播路径,辅助失效分析人员现场诊断。
构件的失效是多种因素共同或耦合作用的结果[13],因此案例中对失效原因的描述涉及多种类型的因素,且不同案例中同一类型失效原因相关联的因素特征不尽相同。
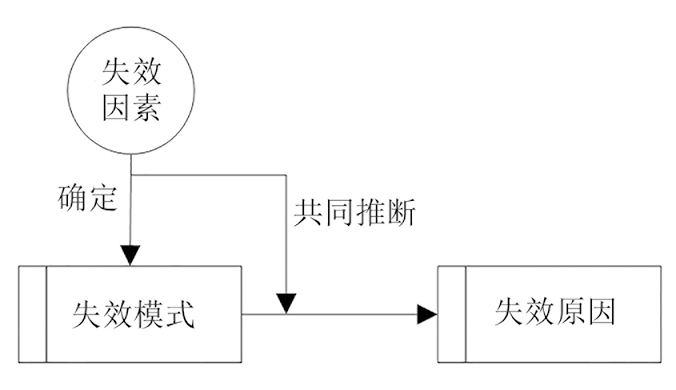
结合失效分析领域专业知识及失效原因排查分析逻辑,对失效分析案例的知识结构进行结构化,建立“失效因素-失效模式-失效原因”三级知识结构(见图2)。其中,失效模式可由一组失效因素确定,基于确定的失效模式,结合其他失效因素的特征,可推断出构件的失效原因。不同失效案例涉及的失效因素、失效模式、失效原因不同。
为了减小失效案例文本记录不规范及同义词对特征提取的影响,降低文本表示后的特征向量维度,提高关联规则挖掘质量,笔者结合各类构件的失效案例,对其失效因素、失效模式、失效原因3个类别下的具体特征进行标准化特征分类,结果如表1所示。
| 类型 | 变量 | 标准化特征分类 |
|---|---|---|
| 失效因素 | waj | 组织特征、断口特征、材料类型、使用工况、失效位置、设备功能类型、零件名称、所属行业等 |
| 失效模式 | wbj | 变形失效、磨损失效、腐蚀失效、断裂失效等 |
| 失效原因 | wcj | 设计原因、制造原因、使用原因、材料原因、工况原因、环境原因、维护原因、装配原因等 |
以失效因素为例,部分标准化的特征名称如表2所示。
| 分类 | 变量 | 标准化名称 |
|---|---|---|
| 组织特征 | wa11 | 杂质相 |
| wa12 | 马氏体 | |
| wa1j | 内氧化 | |
| 使用工况 | wa31 | 酸碱介质 |
| wa32 | 高温 | |
| wa3j | 高压 | |
| 断口特征 | wa21 | 贝纹线 |
| wa22 | 人字纹 | |
| wa2j | 泥瓦状 | |
| 零件名称 | wa41 | 万向节 |
| wa42 | 螺栓 | |
| wa4j | 受电弓 |
针对失效分析案例文本特点,主要进行以下预处理工作。
(1)文本清洗。通过分析失效分析案例文本结构,发现案例一般由前言、背景、来样情况、试验仪器、试验结果(宏观分析、微观分析、化学成分分析及力学性能测试等)、分析与讨论、结论等部分组成,各部分内容具有半结构化的特点,人工编写正则表达式,对其进行清理,例如来样情况的提取,范式为:\n\d{0,1}.{0,3}( :来样|前言|背景).+\n2.{0,4}\n。
(2)文本分词及去停用词。考虑到失效分析案例文本包含大量专业词汇,为避免专业词汇无法被准确识别导致的分词结果不满足后续文本挖掘需求情况,构建失效分析专业词库及停用词词库(见图3)。其中失效分析专业词库主要包含各专业部门设备名称及专业术语,通用词库包含了用于去除文本中无意义项的停用词库及语义词库。
基于失效分析案例文本的分词结果,应用TF-IDF算法进行文本特征提取,建立失效分析案例文本特征向量。
失效分析案例可被表示为一个规范化的特征向量,该特征向量由特征项及其对应的权重构成,其计算方法如式(1)所示。
| (1) |
式中:wi为文档d的特征项,i=1,2,3,…;n为特征项的数量;αi为特征项wi在文档d中的权重。
其中需要注意的是,对于失效案例文本,特征项wi由失效因素集A、失效模式集B、失效原因集C构成,其计算方法如式(2)所示。
| (2) |
式中:waj∈A,wbj∈B,wcj∈C,j=1,2,3,…;m为常量;k为常量。
对于构成失效分析案例文本特征向量的特征项,关注失效因素、失效模式与失效原因在每篇文档中的权重表现,其中失效原因和失效模式在每篇案例中是二值变量,权值为{0,1},即当该案例的失效原因为wcq时,该特征项对应的权值计算方法如式(3)所示。
| (3) |
式中:q为常量。
失效模式集B中的特征项权值取值原则与失效原因相同。
对于构成失效分析案例特征项的失效因素集,其对应的权值可采用TF-IDF方法获得。传统TF-IDF包含词频和逆文档频率两部分,该方法得到的TI值越大,说明词项携带的信息量越大,对于所在文本可认为该词项越关键,因此所有词项及其TI值可构成所在文档特征向量。
传统TF-IDF方法是以所有案例文本为基数计算逆文档频率I,然而对于不同失效模式,各失效因素对其影响的程度不同,以所有案例文本为基数计算各失效因素的I值无法体现其在某种失效模式下的重要性。因此对于失效分析案例,首先按失效模式对文档进行分类,分别计算在不同失效模式下失效因素的TI值,将其作为其在每篇文档中的权值,计算方法如式(4)所示。
| (4) |
式中:T(i,j)为文本j中第i个词的词频,反映词语在某文档中的出现频率,出现频率越高,其值越大;I(ib)为第i个词在失效模式为b的案例集中的逆文档频率,反映是否对文档具有区分性,词语在不同文档中出现的次数越多,I值越小。
I值的计算方法如式(5)所示。
| (5) |
式中:nb为失效模式b的案例集中文本总数;D(ib)为失效模式b的案例集中包含词i的文本数。
关联规则挖掘是数据挖掘最为关键的分支之一,关联规则挖掘是指在大量的数据集中识别和挖掘出事物间隐含的关联关系及依存规律[14]。通过对历史失效分析案例的挖掘,可以进一步发现失效因素、失效模式,以及失效原因之间的关联关系,辅助分析失效因素与失效原因之间的传播路径,实现产品失效原因推理的解耦。
常见的关联规则挖掘算法包括Apriori、FP-Growth及Eclat等。其中,Apriori算法是最常见的基于频繁项集的关联规则挖掘算法,其递归地生成候选项集,并利用剪枝策略来减少计算量[15]。相较于其他关联规则算法,Apriori算法简单易懂,且适合于中小型数据集或对可解释性要求较高的应用场景。因此,考虑到失效分析案例挖掘数据规模和关联路径解耦的应用需求,笔者采用Apriori算法实现对失效分析案例的分析挖掘。
基于失效分析案例文本挖掘方法框架,结合失效分析实际应用场景,提出了基于Apriori算法的两阶段失效分析文本关联规则挖掘方法,并以某船舶单位的失效分析案例为应用场景,对该方法进行了应用验证。
由失效原因、失效模式、失效因素及其对应权重构成的失效分析案例特征矩阵具有高维、稀疏的数据特征,直接应用Apriori算法对其进行关联规则挖掘,挖掘出的关联规则多为本身即具有强关联特性的失效分析领域知识,如关联规则“疲劳裂纹→疲劳断裂”,不能挖掘出更多潜在的关联关系。因此,结合实际的失效分析问题排查逻辑,基于“失效因素-失效模式-失效原因”三级的知识结构,可以分两个阶段对失效分析词项文本矩阵进行频繁集检索,实现降低每个阶段特征维度,提高挖掘效果。
建立了两阶段失效分析文本关联规则挖掘方法,通过“失效因素→失效模式”关联规则挖掘、“失效模式+失效因素→失效原因”关联规则挖掘两个阶段,对失效分析文本特征矩阵进行关联规则分析,辅助挖掘建立失效因素和失效原因间的传播路径。
步骤1:按失效模式对失效分析文本进行分组,分别计算各失效因素在不同分组下的I值,以及各失效因素在不同文本中的I值,得到不同失效模式下各失效文本中失效因素的TI值,将其作为各文本的特征向量。
步骤2:对于获得的不同失效模式下各文本的失效因素特征值矩阵,对其进行二值化处理,即设定特征阈值αmin,当失效因素特征值αi>αmin时,特征值α1取为1;当失效因素特征值αi<αmin时,特征值α1取为0。
步骤3:设定支持度阈值Smin,应用Apriori算法分别挖掘各失效模式下频繁项集及其支持度。其中,频繁项集是失效因素集合的子集。
步骤4:对于步骤3生成的频繁失效因素集,计算各失效模式下,频繁失效因素集的置信度,即失效因素集中所有失效因素发生时,该失效模式发生的概率。设定置信度阈值Cmin,置信度大于Cmin的失效因素集与失效模式构成一组强关联规则,即关联规则为失效因素集→失效模式。
步骤1:对于各失效模式,建立剩余失效分析特征矩阵,该矩阵元素由剩余失效因素集、失效原因集及对应权重构成。其中,剩余失效因素集为失效因素全集与该失效模式的频繁失效因素集的差集。
步骤2:设定支持度阈值Smin,应用Apriori算法分别挖掘剩余失效分析特征矩阵中的频繁项集及其支持度。其中,频繁项集由3个部分组成,即{失效模式wa,剩余失效因素集Bothers,失效原因wc}。
步骤3:对于步骤2生成的频繁项集,计算失效模式与剩余失效因素集对于失效原因的置信度,即在失效模式wa下,特定剩余失效因素Bothers发生时,构件的失效原因是wc的概率。设定置信度阈值Cmin,置信度大于Cmin的失效因素集与失效模式构成一组强关联规则,即关联规则为{失效模式wa,剩余失效因素集Bothers}→失效原因wc。
基于“失效因素→失效模式”关联规则挖掘、“失效模式+失效因素→失效原因”关联规则挖掘两个阶段生成的关联规则,可绘制失效因素-失效模式-失效原因影响路径及权重的可视化图,辅助进行失效原因诊断。
分析数据来源于某船舶公司2016—2024年的失效案例文本。由于失效原因、失效模式及失效元素涉及范围较广,笔者仅以失效模式为疲劳断裂的554个失效分析案例为例,进行关联规则挖掘。试验模型采用Python3.2语言及scikit-learn库实现。
首先,对失效分析案例数据进行标准化,建立包含表1和表2内容的失效分析特征分类和特征标准化的专业词库,词库包含16个特征分类,以及184个标准化特征,结果如表3所示。
| 类型 | 特征分类 | 特征数量/个 | 类型 | 特征分类 | 特征数量/个 |
|---|---|---|---|---|---|
| 失效因素 | 组织特征 | 13 | 失效模式 | 变形失效 | 3 |
| 断口特征 | 27 | 磨损失效 | 7 | ||
| 材料类型 | 8 | 腐蚀失效 | 13 | ||
| 使用工况 | 9 | 断裂失效 | 6 | ||
| 失效位置 | 7 | 失效原因 | 设计原因 | 3 | |
| 设备功能类型 | 6 | 制造原因 | 6 | ||
| 零件名称 | 45 | 使用原因 | 8 | ||
| 所属行业 | 13 | 其他原因 | 10 |
基于以上标准化词库,使用正则表达式对失效分析案例文本进行提取、分词,并对分词后的失效分析案例文本数据,应用TF-IDF算法进行文本特征提取,获得疲劳断裂失效模式下各案例文本的词项文本矩阵,获取各失效因素在不同案例文本中的特征权重。
基于权重矩阵,使用前述基于Apriori算法的两阶段失效分析文本关联规则挖掘方法进行关联规则挖掘。进行挖掘前,需要设定合适的最小支持度,其设定值关系到挖掘得到的关联规则是否具有实际意义和应用效果。选择最小支持度有多种方法,采用以项集平均支持度为基准,在支持度标准偏差允许的范围内,通过若干次最小值支持度阈值调整的方法,选择能得到适中频繁项集的结果[16]。
对于第一阶段“失效因素→失效模式”关联规则挖掘,在本算例中首先将特征阈值αmin设定为0.01,对特征矩阵进行二值化处理,并将最小支持度Smin设定为0.025,最小置信度Cmin设定为0.35,对二值化处理后的特征矩阵进行关联规则挖掘,并筛选出后项中各个状态置信度最高的“失效因素-失效模式”强关联规则,结果如表4所示。
| 规则 | 前项 | 后项 | 支持度 | 置信度 | 规则 | 前项 | 后项 | 支持度 | 置信度 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 疲劳裂纹 | 疲劳断裂 | 0.169 6 | 0.691 1 | 13 | 螺纹 | 疲劳断裂 | 0.052 3 | 0.475 4 |
| 2 | 夹杂物 | 0.135 3 | 0.348 8 | 14 | 氧化 | 0.052 3 | 0.625 0 | ||
| 3 | 疲劳辉纹 | 0.131 7 | 0.708 7 | 15 | 二次裂纹 | 0.054 1 | 0.468 7 | ||
| 4 | 贝纹线 | 0.122 7 | 0.723 4 | 16 | 铁素体 | 0.046 9 | 0.424 2 | ||
| 5 | 柴油机 | 0.115 5 | 0.551 7 | 17 | 机械损伤 | 0.043 3 | 0.545 4 | ||
| 6 | 多源特征 | 0.110 1 | 0.762 5 | 18 | 回火索氏体 | 0.035 4 | 0.321 4 | ||
| 7 | 塑性变形 | 0.077 6 | 0.333 3 | 19 | R角 | 0.035 1 | 0.533 3 | ||
| 8 | 韧窝 | 0.077 6 | 0.346 7 | 20 | 根部,螺纹 | 0.169 6 | 0.894 7 | ||
| 9 | 螺栓 | 0.064 9 | 0.455 6 | 21 | 合金,疲劳裂纹 | 0.032 4 | 0.857 1 | ||
| 10 | 弯曲 | 0.063 2 | 0.564 5 | 22 | 合金,贝纹线 | 0.028 8 | 0.888 8 | ||
| 11 | 线源 | 0.059 5 | 0.647 0 | 23 | 弯曲,疲劳裂纹 | 0.043 3 | 0.705 8 | ||
| 12 | 磨损 | 0.059 5 | 0.423 0 | 24 | 二次裂纹,疲劳裂纹 | 0.028 8 | 0.739 1 |
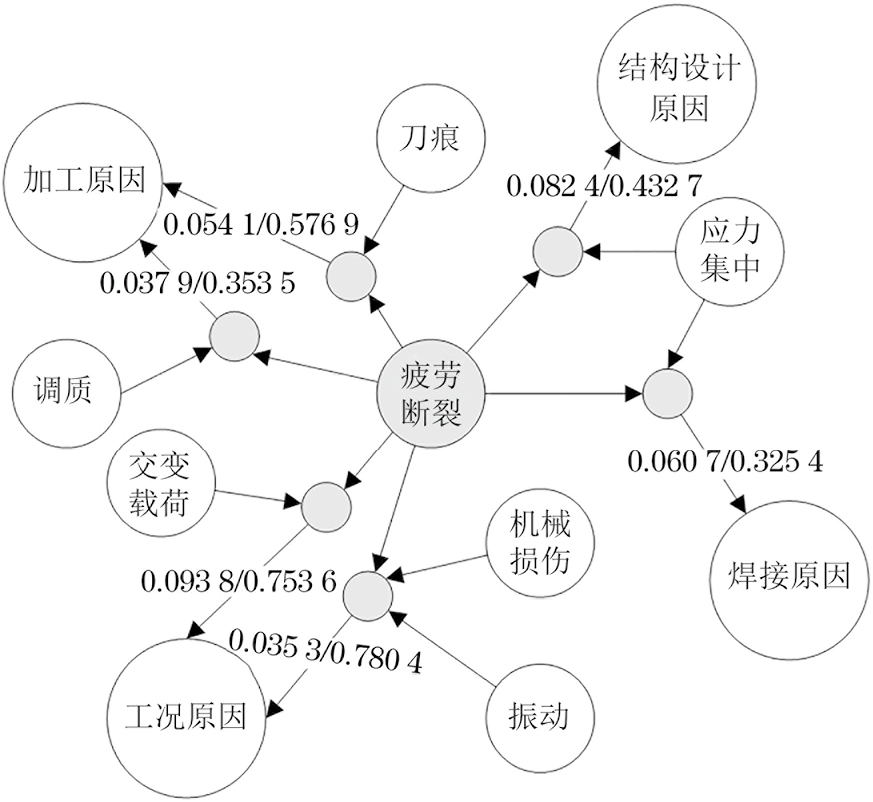
对于得到的“失效因素-失效模式”强关联规则,以“失效因素-确定-失效模式”三元组为基本组成单位,建立失效分析知识图谱。“失效因素-确定-失效模式”知识图谱如图4所示,其中浅色圆形实体为失效因素,深色圆形实体为失效模式,箭头方向及对应权重代表失效因素发生时,其对所指向的失效模式发生的支持度和置信度。
对于第二阶段“失效模式+失效因素→失效原因”关联规则挖掘,在本算例中将最小支持度Smin设定为0.025,最小置信度Cmin设定为0.35,对特征矩阵进行关联规则挖掘,并筛选出后项中各个状态置信度最高的“失效模式+失效因素→失效原因”强关联规则,结果如表5所示。
| 规则 | 前项 | 后项 | 支持度 | 置信度 |
|---|---|---|---|---|
| 1 | 交变载荷、疲劳断裂 | 工况原因 | 0.093 8 | 0.753 6 |
| 2 | 刀痕、疲劳断裂 | 加工原因 | 0.054 1 | 0.576 9 |
| 3 | 应力集中、疲劳断裂 | 焊接原因 | 0.060 7 | 0.432 7 |
| 4 | 应力集中、疲劳断裂 | 结构设计原因 | 0.082 4 | 0.325 4 |
| 5 | 高温、疲劳断裂 | 工况原因 | 0.037 9 | 0.656 2 |
| 6 | 疏松、疲劳断裂 | 冶金原因 | 0.0703 | 0.371 4 |
| 7 | 渗碳、疲劳断裂 | 加工原因 | 0.025 2 | 0.368 4 |
| 8 | 调质、疲劳断裂 | 加工原因 | 0.037 9 | 0.353 5 |
| 9 | 机械损伤、振动、疲劳断裂 | 工况原因 | 0.035 3 | 0.780 4 |
对于得到的“失效模式+失效因素→失效原因”强关联规则,以“失效模式+失效因素-推断-失效模式”三元组为基本组成单位,在已建立的失效分析知识图谱中引入新数据、补充实体关系和属性。“失效模式+失效因素-推断-失效模式”知识图谱如图5所示,其中浅色小圆形实体为失效因素,深色大圆形实体为失效模式,深色小圆形代表箭头关联的失效因素、失效模式的组合;浅色大圆形为失效原因,深色小圆形箭头方向及对应权重代表其对应失效因素、失效模式同时发生时,对所指向失效原因发生的支持度和置信度。
通过上述试验,获得了疲劳断裂模式下由失效因素、失效模式、失效原因构成的频繁项集及关联规则,并采用知识图谱的方式,对关联规则进行存储,建立了失效因素及失效原因间的可视化传播路径。将失效分析知识图谱应用于失效原因辅助诊断场景,可辅助产品失效原因推理的解耦,提高诊断效率。
针对产品失效分析复杂性高、分析效率低且过于依赖专家经验的问题,应用自然语言处理及数据挖掘等技术,提出了一种基于Apriori算法的失效分析案例文本挖掘方法,该方法中包含失效分析案例文本预处理方法、基于TF-IDF算法的失效分析案例文本特征表示模型,以及基于Apriori算法的两阶段失效案例关联分析方法3个主要部分。该方案通过对失效案例数据的实际特点及结构进行深度分析,并应用关联规则挖掘方法,分两个阶段实现了失效因素、失效模式、失效原因间的关联路径挖掘,建立了一种产品失效原因诊断和故障作用机制解释的方法,该方法在辅助提高失效原因排查效率、准确性方面具有重要作用。
应用该方法对某船舶单位2016—2024年失效分析案例进行关联规则挖掘,建立了失效分析领域标准化特征及疲劳断裂失效模式下各特征在不同案例下的特征矩阵,并应用Apriori算法分两个阶段挖掘获得疲劳断裂模式下由失效因素、失效模式、失效原因构成的频繁项集及关联规则。将挖掘获得的关联规则存储在知识图谱中,建立了失效因素及失效原因间的可视化传播路径。该方法对辅助产品失效原因推理的解耦、提高诊断效率具有良好的技术支撑作用。
关联规则挖掘在发现数据中的模式方面具有强大的能力,但存在计算复杂度高,不适合处理高维、稀疏数据的问题。随着失效分析案例的逐年增多,为了克服这些缺点,未来将结合神经网络等方法来提高其效果和效率。
文章来源——材料与测试网
浙江国检检测技术股份有限公司 版权所有 【暂无】 百度统计
全国统一服务热线:400-1188-260
客服手机号:13372307781
电话:400 1188 260 质量投诉 +86-573-86161208
邮箱:shhgj@chinazbj.com
地址:浙江省嘉兴市海盐县武原街道丰潭路777号
备案号:浙ICP备05056915号
 浙公网安备 33042402000106号
浙公网安备 33042402000106号
技术支持:追马网
 客服微信号
客服微信号
 微信公众号
微信公众号